EUOS25 Challengeにて優勝しました (Transmittanceカテゴリー)
EU-OPENSCREENとSLASが主催するEUOS25 Challenge[1]において、我々のチームyumizはTransmittanceカテゴリーのブラインドテストで1位となりました(Fluorescenceカテゴリーでは6位でした)。
優勝チームである我々のチームには、ボストンで開催されるSLAS2026 International Conference & Exhibitionにて賞金€1,000が授与されるとのことです。 また、優勝チームと、性能に有意差のない結果を出したチームは、SLAS journalにて研究またはプロトコルを発表するよう招待されるそうです。
このブログでは、我々のチームの解法を簡単に紹介したいと思います。 なお、実際のコード等はohuelab/euos25-solutionにて公開しているので詳細はそちらを参照してください。
コンペ概要
EUOS25 Challengeは化合物の光の吸収・蛍光を予測するデータサイエンスコンペティション(Kaggleのようなもの)で、一昨年も似たようなコンペが開催されていたようです。 数万件の訓練データを用いて、Transmittanceは特定波長の光の吸収の有無を、Fluorescenceは蛍光の有無を予測する二値分類タスクになっていて、TransmittanceとFluorescenceの2つのカテゴリーでそれぞれ優勝が決められました。
それぞれ以下のように2つのサブタスクに分かれており、各サブタスクのROC AUCの平均で順位が決まります。
- Transmittanceサブタスク1a: 340 nmで透過率≤70%の化合物を予測
- Transmittanceサブタスク1b: 450~679 nmの範囲で平均して透過率≤70%の化合物を予測
- Fluorescenceサブタスク2a: 励起340 nm・発光450 nmの条件で、蛍光強度がしきい値を超える化合物を予測
- Fluorescenceサブタスク2b: 励起/発光の波長ペアが480/540、525/598、560/610 nmのいずれかの条件で、蛍光強度がしきい値を超える化合物を予測
特に、サブタスク1bと2bではラベルに不均衡があることが知られており(蛍光タスクでは0.23%、透過タスクでは1.5%のみ正例)、これらのサブタスクに対しても高い性能を発揮するモデルをいかに構築できるかが争点だったと思います。
コンペは2025年10月から2026年1月まで開催されていました。
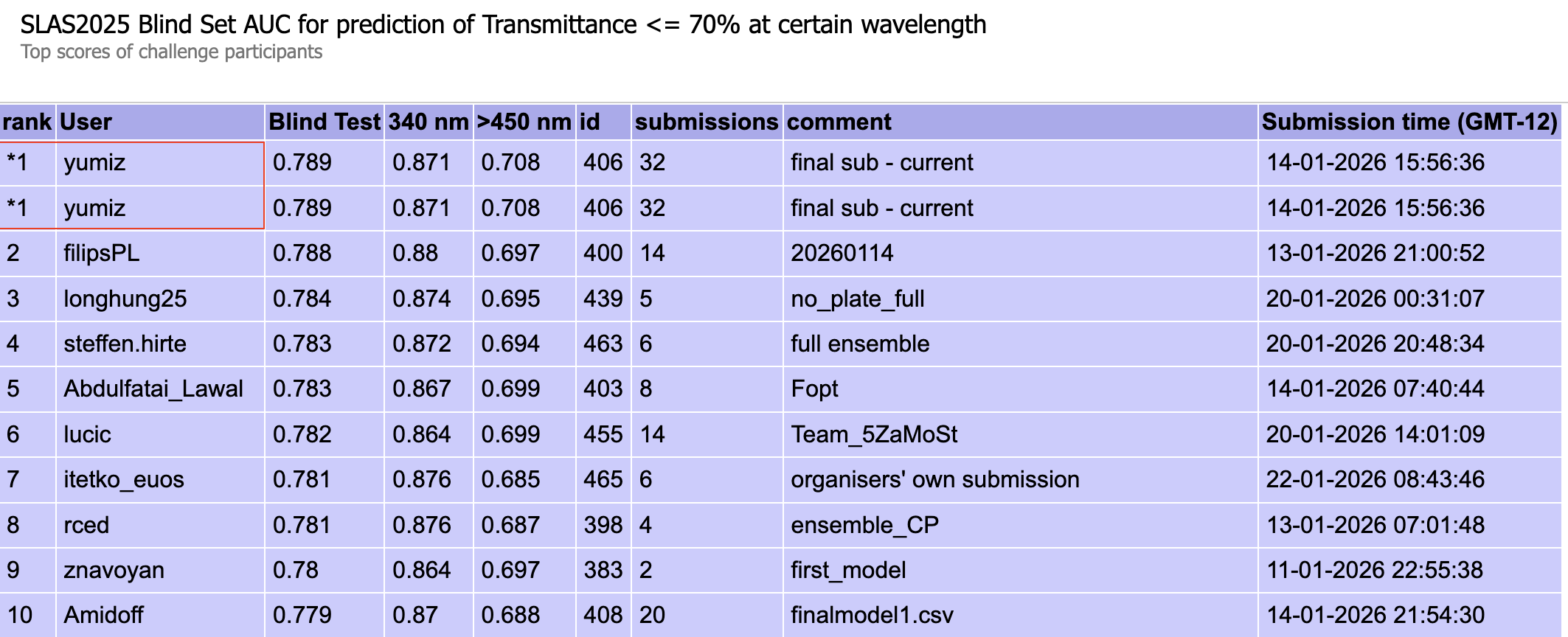
図1: Transmittanceタスクのブラインドテスト結果
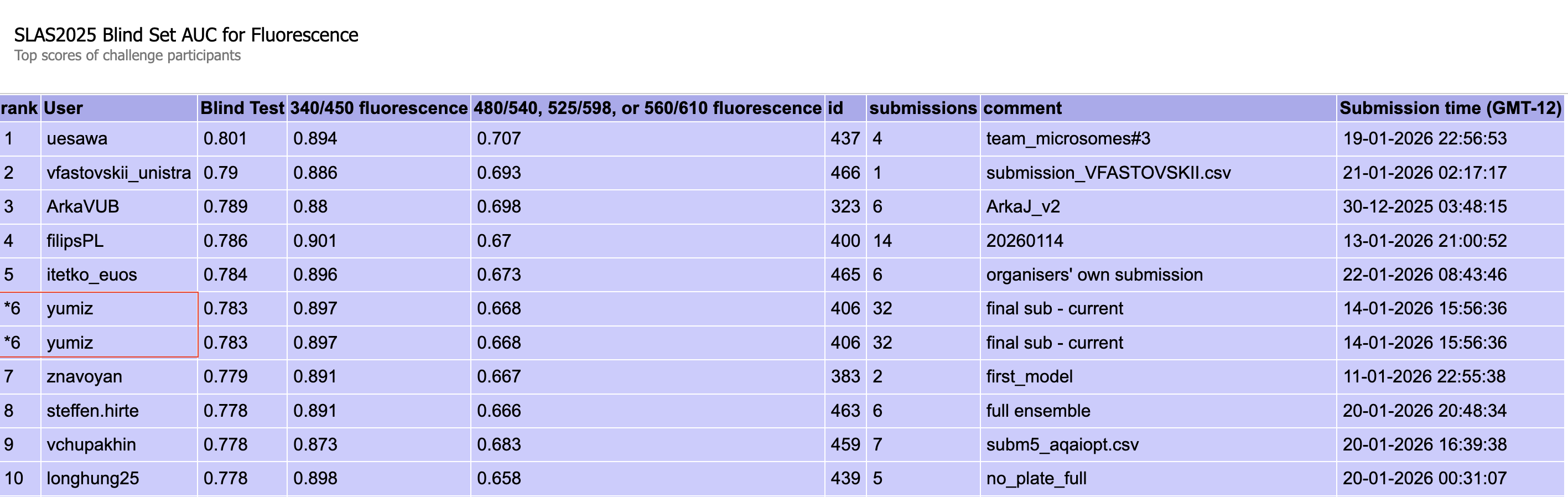
図2: Fluorescenceタスクのブラインドテスト結果
チーム構成
チームyumizは自分を含む東京科学大学大上研究室の学生3人で構成されています。 最初は各人が個別に参加していたものの、途中から主催者に連絡したうえでチームマージしました。 ただ、3人でアンサンブルしても性能は改善せず、最終提出にはチームを組む以前に自分が構築したアンサンブルモデルのみを用いました。 とはいえ、色々ディスカッションし、情報共有をしたことで、これ以上やれることがなさそうというのが分かったので、チームを組む意味は十分にあったと思います。
解法
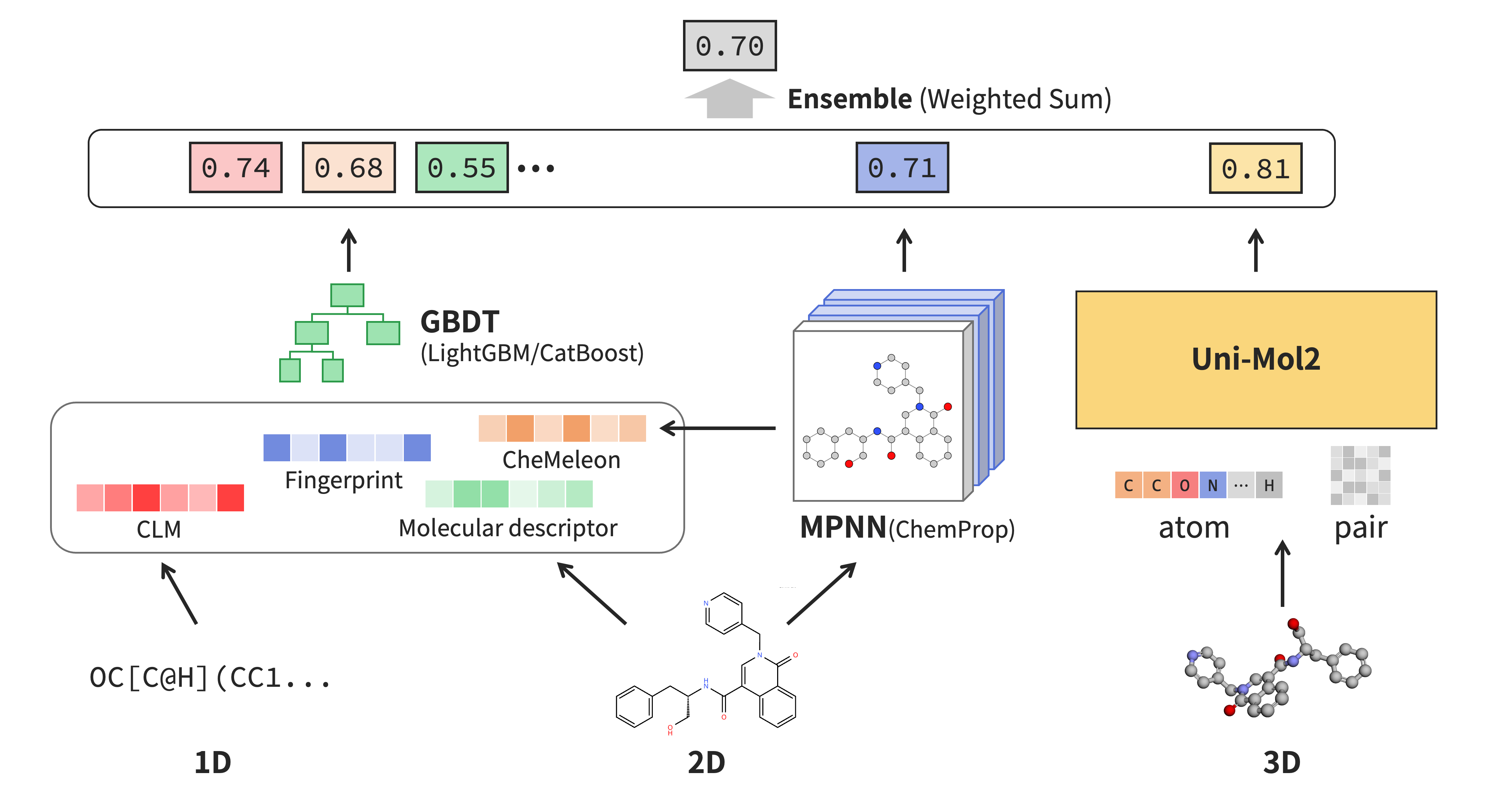
図3: チームyumizの優勝解法の概要図
提出モデルを端的に言うと、「様々な予測モデルをいい感じにアンサンブルした」だけです。
まず、LightGBMやCatBoostなどの勾配ブースティング決定木を用いた予測モデルを以下の特徴量を単独、組み合わせるなど様々なパターンで学習し、CV性能の高いモデルを採用しました。
- 化合物言語モデル(ChemBERTa[2])の潜在表現
- RDKitやMordredで計算した化合物記述子
- ECFP4を用いた分子フィンガープリント
- CheMeleon[3](Mordred記述子で事前学習したChemPropベースのMPNNモデル)の潜在表現
それから、ChemProp[4]やCheMeleonを用いた予測モデルも構築しました。 さらにUni-Mol2[5](84M, 310M)を用いて、3次元構造を利用した予測モデルも構築しました。 これらを交差検証でのスコアが良くなるように単に重み付け和によるアンサンブルを行い、提出しました。
特徴として、分子の1次元情報(SMILES)、2次元情報(構造)、3次元情報(3Dコンフォーメーション)をそれぞれ利用しています(コンペ中に意識していたと言うより、最終的にこれに収束したというだけですが)。
それから、以下のような細かい工夫もしています。
- 塩の除去などの基本的なSMILESの前処理
- Murcko scaffoldsデータ分割で5分割の交差検証
- GBDT系にはnested cross validation + Optunaでハイパーパラメータチューニング
- Focal Lossを用いた不均衡データへの対処
- ChemPropを用いたマルチタスク学習
- 透過率タスクにおいては回帰モデルの使用を検討
結果
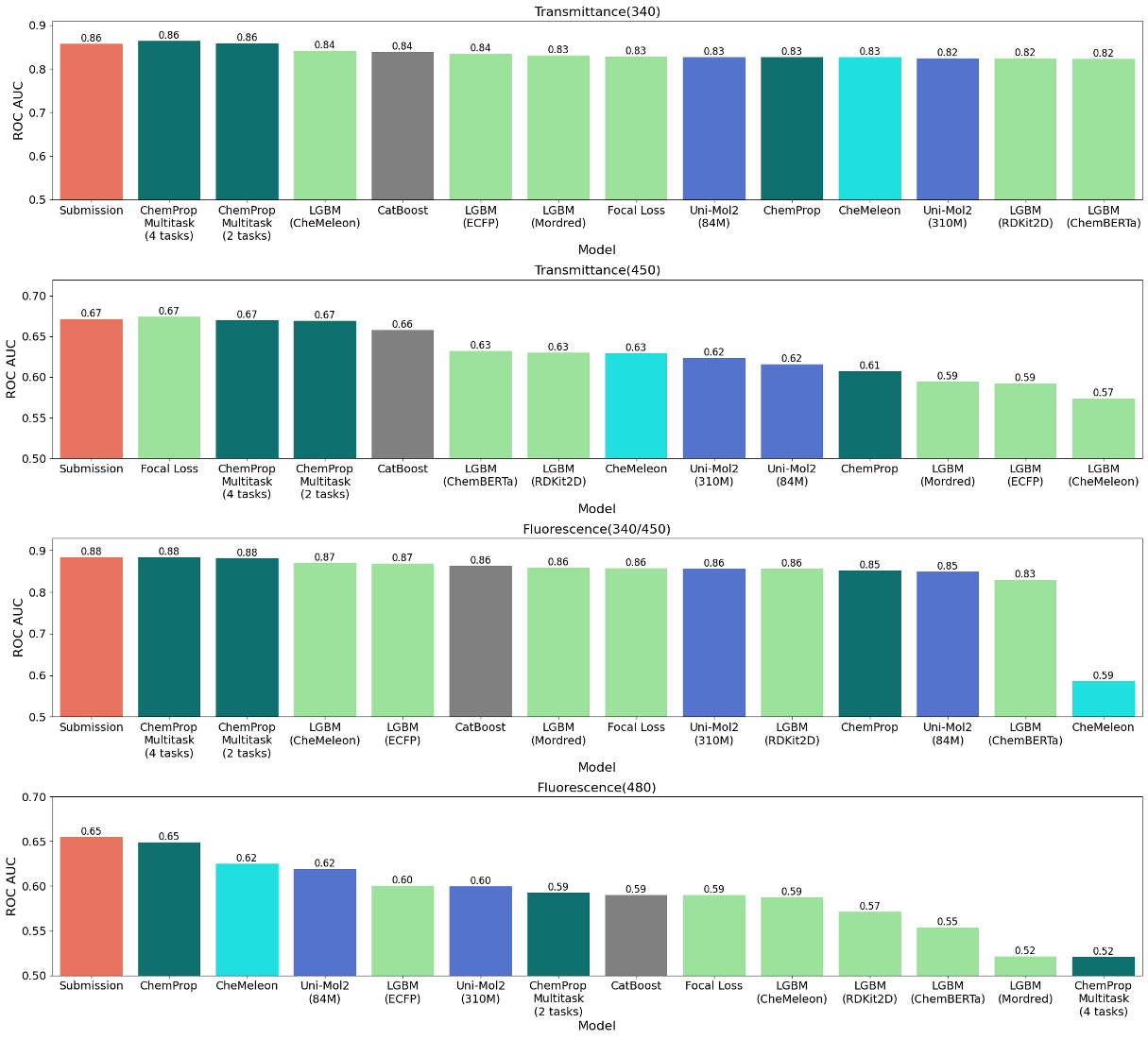
図4: 各タスクにおけるの手法ごとのリーダーボードでの性能
図はコンペ終了後にリーダーボードのテストセットを用いて複数の単独モデルの予測性能と最終提出モデルの予測性能を比較したものです(全ての単独モデルをアンサンブルに用いたわけではない)。 全てのタスクにおいて一貫した傾向は見られませんでしたが、最終提出モデルの性能は一貫して良いことがわかります。 アンサンブルによって多様な情報源の組み合わせることが頑健かつ汎化性能の高い予測モデルの構築に繋がったのだと思います。
それから、Public/Privateリーダーボードでのスコアは以下の通りです。各タスクでPrivateの方がPublicより高い事がわかります。また、パブリックリーダーボードで我々よりも上位のチームはたくさんいますが、おそらくリーダーボードに過適合しています。 scaffold分割による交差検証をして汎化性能が落ちないようにするのは定番の工夫だと思ってましたが、ここまで大きく順位が入れ替わるのはやや意外でした。
表1: Public/Privateリーダーボードでのスコア
| タスク | Public | Private |
|---|---|---|
| Transmittance subtask 1a | 0.857 | 0.871 |
| Transmittance subtask 1b | 0.670 | 0.708 |
| Fluorescence subtask 2a | 0.883 | 0.897 |
| Fluorescence subtask 2b | 0.655 | 0.668 |
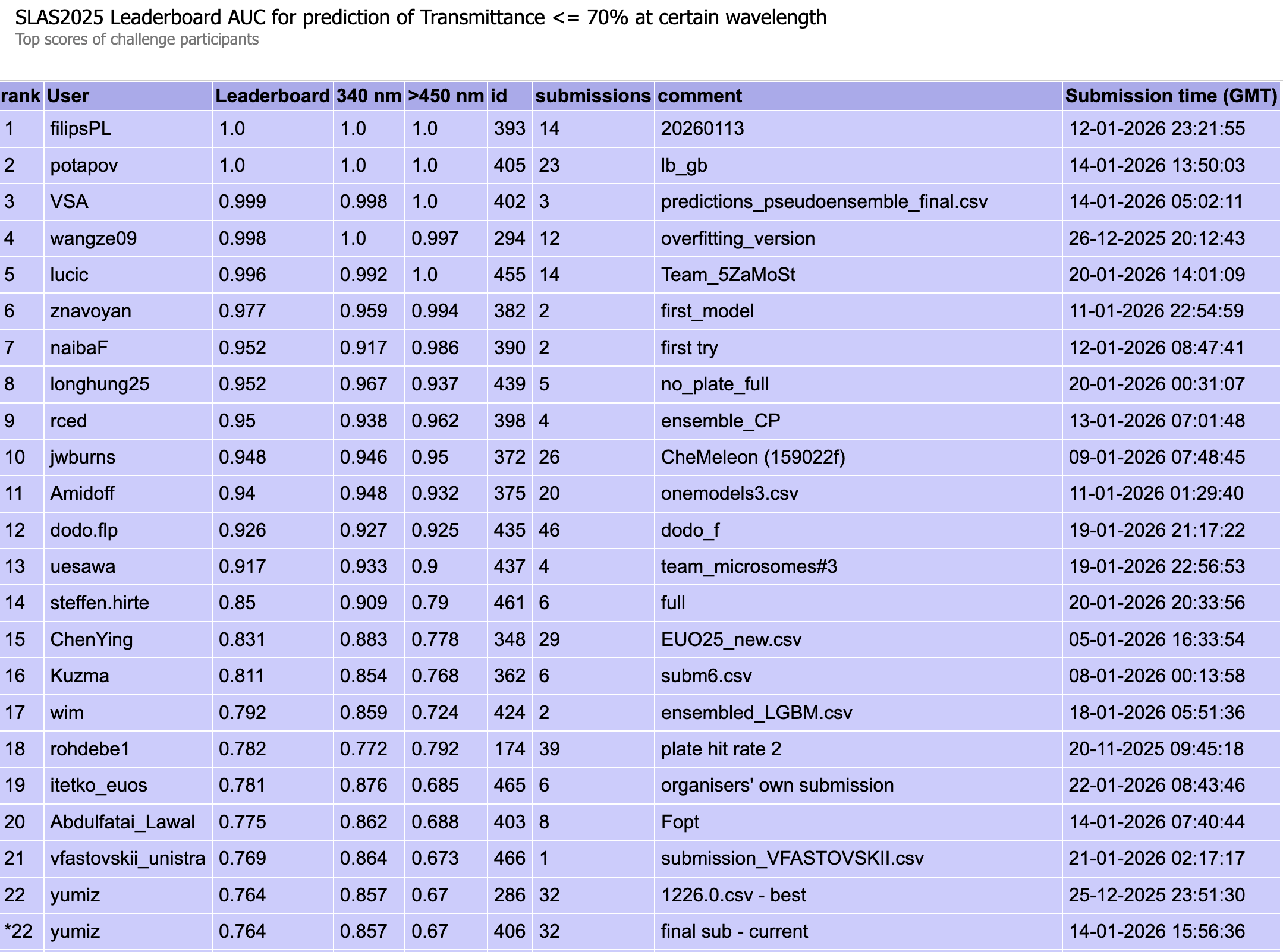
図5: Transmittanceタスクのパブリックリーダーボードの順位
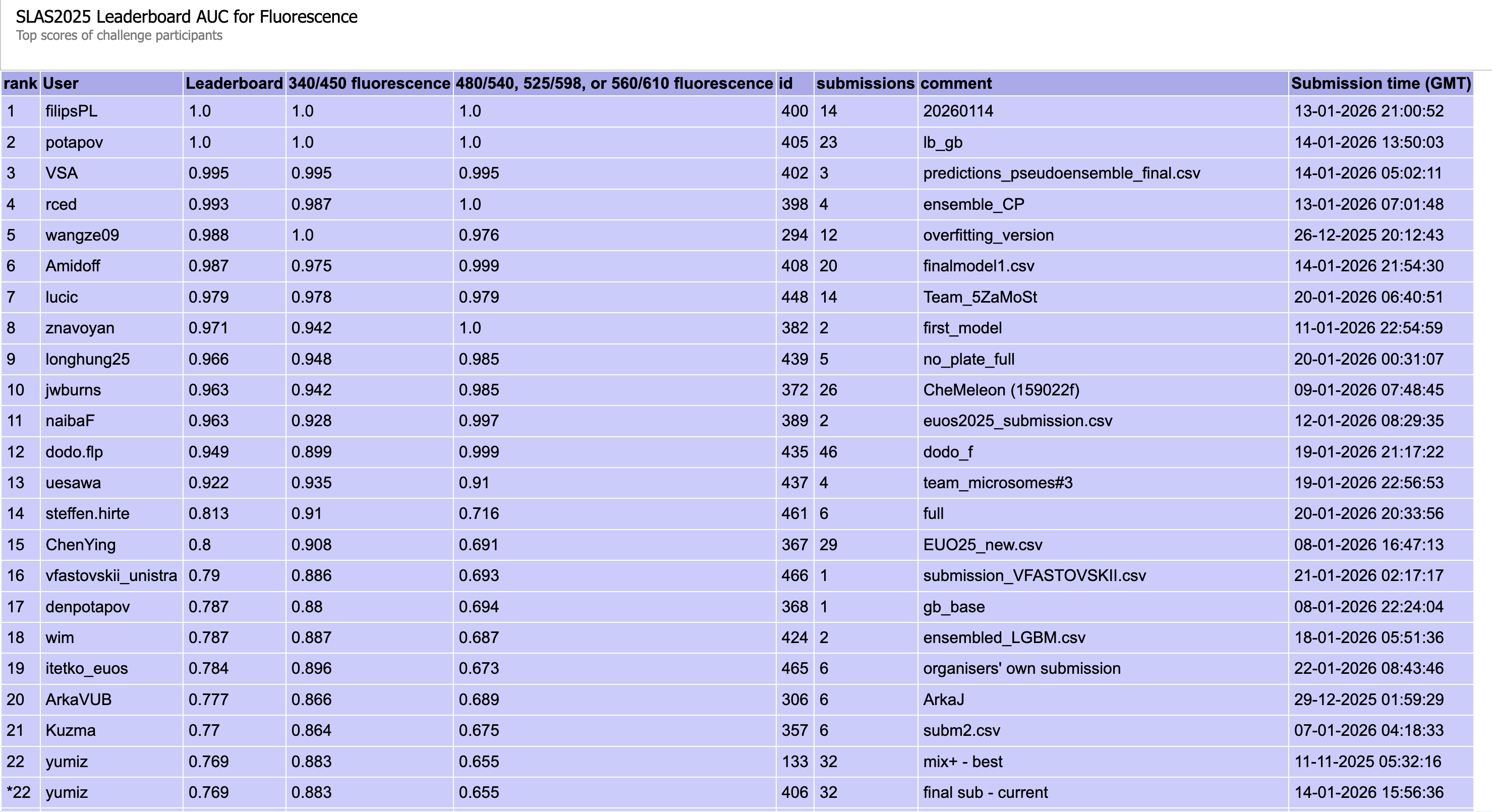
図6: Fluorescenceタスクのパブリックリーダーボードの順位
well/plateの偏りについて
余談ですが、主催者の説明ではwell/plateによる学習データの分布の偏りを正規化する目的(予測に使ってはいけない)でその情報を使っても良いと言及があったのですが、試したところあまり効果がありませんでした。
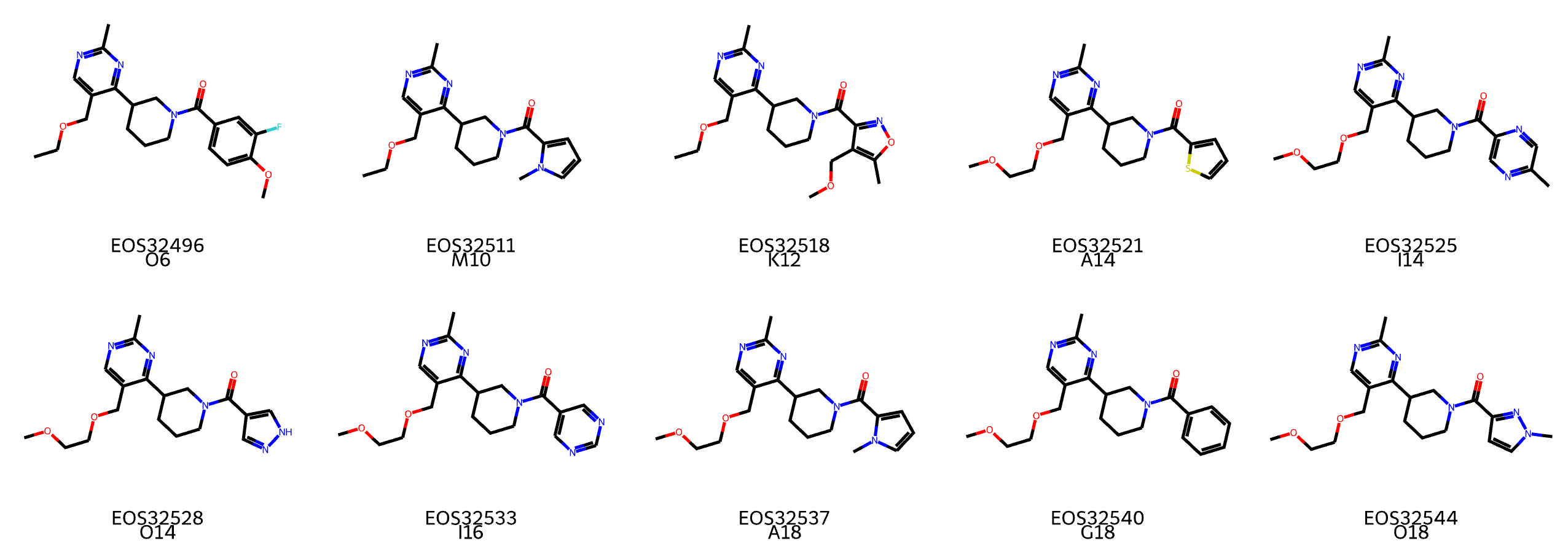
図7: C1096のプレートにおけるTransmittance(450nm)正例において非常に類似した正例
例えば、C1096というプレートには図のようにTransmittance(450nm)の正例において非常に類似した分子が多く含まれていることがわかります。 つまり、well/plateにおけるラベルの偏りが、似た分子が同じプレートに偏っているためなのか、そのwellやplateに問題があるのか明らかでないために補正が効かなかったのだと考えられます。
おわりに
1位を取れてよかったです。
参考文献
- [1] EUOS25 Challenge | Online Chemical Modeling Environment
- [2] Chithrananda, Seyone, et al. "ChemBERTa: Large-scale self-supervised pretraining for molecular property prediction." arXiv [cs.LG], 19 Oct. 2020
- [3] Burns, Jackson, et al. "Descriptor-Based Foundation Models for Molecular Property Prediction." arXiv [Cs.LG], 18 June 2025
- [4] Heid, Esther, et al. "Chemprop: A Machine Learning Package for Chemical Property Prediction." Journal of Chemical Information and Modeling, vol. 64, no. 1, Jan. 2024, pp. 9–17.
- [5] Ji, Xiaohong, et al. "Exploring Molecular Pretraining Model at Scale." The Thirty-Eighth Annual Conference on Neural Information Processing Systems, 2024